Export Pixie data in the OpenTelemetry format.Learn more🚀
Pixie has an OpenTelemetry plugin!
Ctrl/Cmd + K
Safer Kubernetes Node Pool Upgrades

Hannah Troisi
March 28, 2022 • 6 minutes readSenior Dev Relations Engineer @ New Relic, Founding Engineer @ Pixie Labs
Are you dreading upgrading your cluster to a newer Kubernetes version? There are a few reasons why you might be motivated to upgrade. Perhaps you want to do one of the following:
- Use a new beta API
- Install an application that requires a more recent Kubernetes version
- Follow the best practice of keeping your software up to date
Whatever the reason, it’s worth reviewing your upgrade process to make sure you are minimizing downtime (and anxiety) during upgrades.
Which components get upgraded?
A Kubernetes cluster consists of a set of nodes and a control plane. The worker nodes host pods which run your containerized applications. The control plane manages the worker nodes and pods in the cluster.
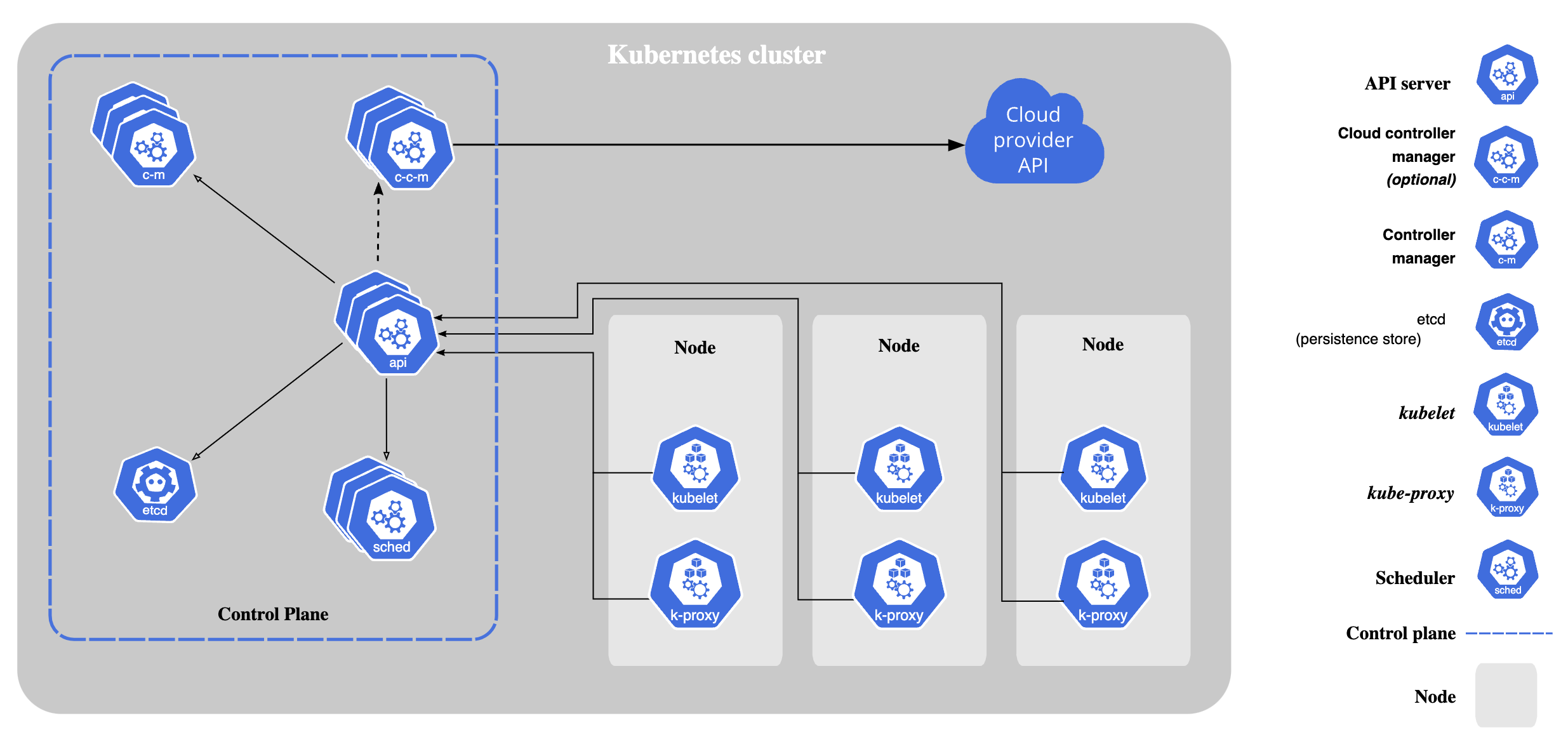
The components of a Kubernetes cluster (from kubernetes.io).
To upgrade a Kubernetes cluster, you’ll upgrade both of these components in the following order:
- Upgrade the control plane
- Upgrade worker nodes
For self-hosted and managed clusters, upgrading the control plane is very straightforward. This post will instead focus on minimizing downtime for the worker nodes upgrade.
Upgrading Worker Nodes
There are two strategies for upgrading the Kubernetes version on worker nodes:
- In-place upgrade (also called a rolling update)
- Out-of-place upgrade
For an in-place upgrade, one by one the nodes are drained and cordoned off so that no new pods will be scheduled on that node. The node is then deleted and recreated with the updated Kubernetes version. Once the new node is up and running, the next node is updated. This strategy is visualized in the animation below:

Animation showing an in-place upgrade for the nodes in a Kubernetes cluster (from Fairwinds.com).
The advantage of an in-place upgrade is that it requires minimal additional compute resources (a single additional node). The downside to this strategy is that it can take quite a bit of time as nodes are drained and upgraded one at a time in series. Additionally, pods may need to make more than 1 move as they are shuffled around during the draining of nodes.
For an out-of-place upgrade, a fresh node pool is created with the new Kubernetes version. Once the new nodes are all running, you can cordon the old node pool, drain the old nodes one by one, and then delete the old node pool. This strategy is visualized in the animation below:
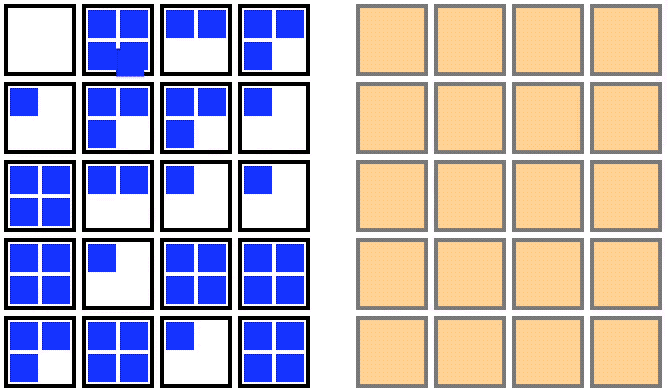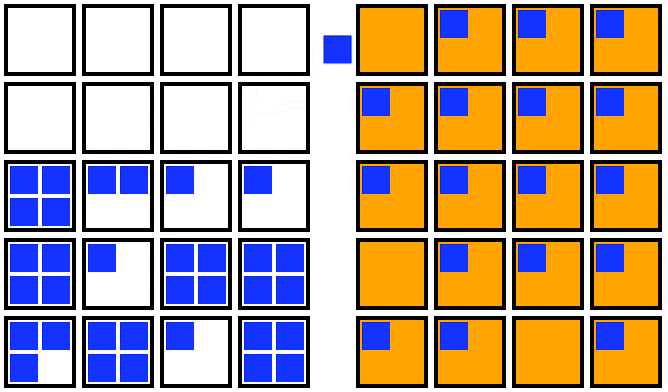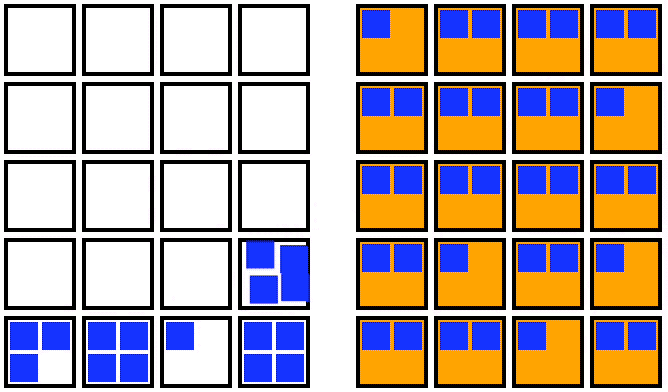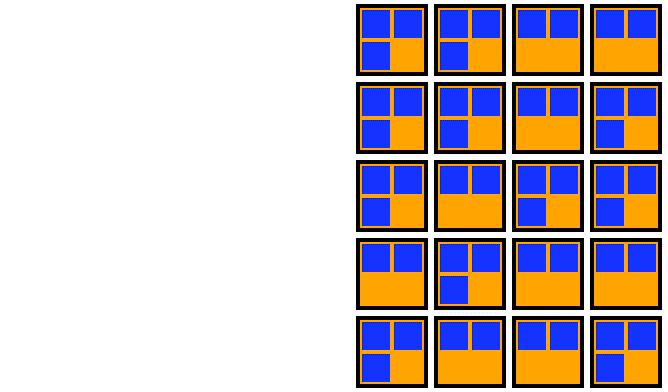
Animation showing an out-of-place upgrade for the nodes in a Kubernetes cluster (from Fairwinds.com).
An out-of-place upgrade requires a temporary doubling of compute resources in exchange for a shorter upgrade window. The decrease in upgrade duration results from the parallelization of the startup time of the new upgraded nodes, as well as the minimization of the movement of the pods. In this strategy, pods make a single move from the old node to the new upgraded node.
Assuming you’re okay with the temporary increase in compute resource utilization, we recommend utilizing the out-of-place upgrade strategy to speed things up.
Configuring K8s Resources
Whichever worker node upgrade strategy you choose will involve shuffling of your pods from the original nodes to an upgraded node. If your resources are not properly configured, this can cause downtime. Let’s take a look at a few potential pitfalls.
Standalone Pods
A pod is the smallest deployable object in Kubernetes. It represents a single instance of an application running in your cluster. Pods are ephemeral; if a pod is evicted from a node, the pod does not replace itself. Because pods are not self-healing, it is not recommended that you create individual Pods directly. Instead, use a controller such as a Deployment to create and manage the Pod for you.
To minimize downtime, ensure that all your pods are managed by a ReplicaSet, Deployment, StatefulSet or something similar. Standalone pods might need to be manually rescheduled after an upgrade.
Deployments
Most of the pods in your cluster are likely controlled by a Deployment. A Deployment represents a set of identical pods with no unique identities. A Deployment increases availability by managing multiple replicas of your application and deploying replacements if any instance fails.
To eliminate downtime, ensure that your applications have a PodDisruptionBudget (PDB). A PDB helps provide higher availability by limiting the number of pods of a replicated application that are down simultaneously.
For example, the following PDB declares that 80% of the pods with the front-end label must be available during a disruption (such as our upgrade). This ensures that the number of replicas serving load never falls below a certain percentage of the total replicas.
apiVersion: policy/v1kind: PodDisruptionBudgetmetadata:name: demospec:minAvailable: 80%selector:matchLabels:name: front-end

Note that you’ll need to ensure that there are more than one replica (at least temporarily, during the upgrade) in order for the nodes to be able to be upgraded.
Daemonsets
A DaemonSet ensures that all (or some) nodes run a copy of a pod. Daemonsets are often used for node monitoring or log collection and do not typically serve traffic. For these use cases, it’s usually acceptable to have a small gap in data during the worker node upgrade.
StatefulSets
A StatefulSet is the Kubernetes controller type used to manage stateful applications, such as databases or messaging queues. Upgrading StatefulSets requires more consideration than upgrading Deployments.
To eliminate downtime, ensure that you have configured the following:
- Add a PodDisruptionBudget (see the explanation in the "Deployments" section). For quorum-based applications, ensure that the number of replicas running is never brought below the number needed for quorum (e.g,
minAvailable: 51%). - Make sure you have more than one replica (at least temporarily, during the upgrade).
- Ensure that any PersistentVolumes are retained.
- For quorum-based applications, make sure you’ve configured a Readiness probe.
StatefulSet Potential Incident #1
To illustrate the importance of a PodDisruptionBudget (PDB) when upgrading a StatefulSet, let’s consider an example cluster that uses STAN, a distributed messaging system.
STAN relies on a Raft consensus for quorum, meaning that a majority (> 50%) of servers need to be available to agree upon decisions. This cluster’s STAN StatefulSet has 5 replicas. If 2 of these replicas fail, the STAN can still operate. However, if more than 2 replicas fail, STAN will not be able to reach quorum and will stop working.
Our example cluster's STAN StatefulSet does not have a PDB. With this configuration, it is possible to lose quorum during an upgrade in the following way:
- Given the lack of a PDB, the control plan indicates that any number of STAN pods can be disrupted.
- This means that the node pool upgrade is able to disrupt more than 50% of the STAN pods at the same time. In this case, 3 of the 5 STAN pods get evicted at once when the first node is drained.
- The 2 remaining STAN pods cannot maintain quorum and this causes irrecoverable loss of data.
This failure mode is visualized in the animation below. The 5 squares represent the 5 STAN pods.

Animation of a loss of quorum for a Raft application during an upgrade. The StatefulSet is missing a PDB.
In this situation, a PDB configured with minAvailable: 51% would have prevented loss of quorum by ensuring that no fewer than 51% of pods are evicted at once from the node that is draining.
StatefulSet Potential Incident #2
To illustrate the importance of Readiness probes when upgrading StatefulSets, let’s consider the same example cluster.
Our example cluster's STAN StatefulSet configures a PDB (with minAvailable: 51%) and a liveness probe, but it lacks a readiness probe. With this configuration, it is possible to lose quorum during an upgrade in the following way:
- The controller follows the PDB and ensures that less than half the STAN nodes are disrupted at a given time. Only 2 STAN pods are initially evicted from the draining node.
- However, given the lack of readiness probes, as soon as the disrupted STAN pods are scheduled and then lively, the controller is allowed to disrupt more pods.
- Since liveliness checks are designed to indicate a running container, STAN marks itself as lively before it starts (or finishes) reading the Raft logs.
- However, given that the 2 STAN pods haven't finished reading the Raft logs, it is not ready to accept traffic.
- If the controller now disrupts more STAN pods, then it’s possible that while we have > 50% lively STAN pods, there are < 50% ready STAN pods (i.e. some of the pods are busy recovering state from the Raft logs).
- The 2 remaining STAN pods cannot maintain quorum and this causes irrecoverable loss of data.
This failure mode is visualized in the animation below. The 5 squares represent the 5 STAN pods. Red squares indicate the pod is not yet lively. Yellow squares indicate the pod is not yet ready.

Animation of a loss of quorum for a Raft application during an upgrade. The StatefulSet is missing a Readiness probe.
In this situation, a readiness probe would have prevented further STAN pods from being disrupted before the newly created STAN pods were ready. The readiness probe could be configured to send an HTTP GET request to the /streaming/serverz monitoring endpoint; this endpoint won't respond to requests until the STAN server is ready.
Conclusion
Upgrading your Kubernetes cluster can be nerve wracking. However, with a basic understanding of the upgrade process and a brief consideration of your various Kubernetes resources, you should be able to minimize downtime during your next upgrade.
Have questions? Need help? Find us on Slack or Twitter.
Related posts






Terms of Service|Privacy Policy
We are a Cloud Native Computing Foundation sandbox project.

Pixie was originally created and contributed by New Relic, Inc.
Copyright © 2018 - The Pixie Authors. All Rights Reserved. | Content distributed under CC BY 4.0.
The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our Trademark Usage Page.
Pixie was originally created and contributed by New Relic, Inc.
This site uses cookies to provide you with a better user experience. By using Pixie, you consent to our use of cookies.