Export Pixie data in the OpenTelemetry format.Learn more🚀
Pixie has an OpenTelemetry plugin!
Ctrl/Cmd + K
Horizontal Pod Autoscaling with Custom Metrics in Kubernetes

Natalie Serrino
October 20, 2021 • 5 minutes readPrincipal Engineer @ New Relic, Founding Engineer @ Pixie Labs
Sizing a Kubernetes deployment can be tricky. How many pods does this deployment need? How much CPU/memory should I allocate per pod? The optimal number of pods varies over time, too, as the amount of traffic to your application changes.
In this post, we'll walk through how to autoscale your Kubernetes deployment by custom application metrics. As an example, we'll use Pixie to generate a custom metric in Kubernetes for HTTP requests/second by pod.
Pixie is a fully open source, CNCF sandbox project that can be used to generate a wide range of custom metrics. However, the approach detailed below can be used for any metrics datasource you have, not just Pixie.
The full source code for this example lives here. If you want to go straight to autoscaling your deployments by HTTP throughput, it can be used right out of the box.
Metrics for autoscaling
Autoscaling allows us to automatically allocate more pods/resources when the application is under heavy load, and deallocate them when the load falls again. This helps to provide a stable level of performance in the system without wasting resources.

Autoscaling the number of pods in a deployment based on deployment performance.
The best metric to select for autoscaling depends on the application. Here is a (very incomplete) list of metrics that might be useful, depending on the context:
- CPU
- Memory
- Request throughput (HTTP, SQL, Kafka…)
- Average, P90, or P99 request latency
- Latency of downstream dependencies
- Number of outbound connections
- Latency of a specific function
- Queue depth
- Number of locks held
Identifying and generating the right metric for your deployment isn't always easy. CPU or memory are tried and true metrics with wide applicability. They're also comparatively easier to grab than application-specific metrics (such as request throughput or latency).
Capturing application-specific metrics can be a real hassle. It's a lot easier to fall back to something like CPU usage, even if it doesn't reflect the most relevant bottleneck in our application. In practice, just getting access to the right data is half the battle. Pixie can automatically collect telemetry data with eBPF (and therefore without changes to the target application), which makes this part easier.
The other half of the battle (applying that data to the task of autoscaling) is well supported in Kubernetes!
Autoscaling in Kubernetes
Let's talk more about the options for autoscaling deployments in Kubernetes. Kubernetes offers two types of autoscaling for pods.
Horizontal Pod Autoscaling (HPA) automatically increases/decreases the number of pods in a deployment.
Vertical Pod Autoscaling (VPA) automatically increases/decreases resources allocated to the pods in your deployment.
Kubernetes provides built-in support for autoscaling deployments based on resource utilization. Specifically, you can autoscale your deployments by CPU or Memory with just a few lines of YAML:
apiVersion: autoscaling/v2beta2kind: HorizontalPodAutoscalermetadata:name: my-cpu-hpaspec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: my-deploymentminReplicas: 1maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 50

This makes sense, because CPU and memory are two of the most common metrics to use for autoscaling. However, like most of Kubernetes, Kubernetes autoscaling is also extensible. Using the Kubernetes custom metrics API, you can create autoscalers that use custom metrics that you define (more on this soon).
If I've defined a custom metric, my-custom-metric, the YAML for the autoscaler might look like this:
apiVersion: autoscaling/v2beta2kind: HorizontalPodAutoscalermetadata:name: my-custom-metric-hpaspec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: my-deploymentminReplicas: 1maxReplicas: 10metrics:- type: Podspods:metric:name: my-custom-metrictarget:type: AverageValueaverageUtilization: 20
How can I give the Kubernetes autoscaler access to this custom metric? We will need to implement a custom metric API server, which is covered next.
Kubernetes Custom Metric API
In order to autoscale deployments based on custom metrics, we have to provide Kubernetes with the ability to fetch those custom metrics from within the cluster. This is exposed to Kubernetes as an API, which you can read more about here.
The custom metrics API in Kubernetes associates each metric with a particular resource:
/namespaces/example-ns/pods/example-pod/{my-custom-metric}
fetches my-custom-metric for pod example-ns/example-pod.
The Kubernetes custom metrics API also allows fetching metrics by selector:
/namespaces/example-ns/pods/*/{my-custom-metric}
fetches my-custom-metric for all of the pods in the namespace example-ns.
In order for Kubernetes to access our custom metric, we need to create a custom metric server that is responsible for serving up the metric. Luckily, the Kubernetes Instrumentation SIG created a framework to make it easy to build custom metrics servers for Kubernetes.

All that we needed to do was implement a Go server meeting the framework's interface:
type CustomMetricsProvider interface {// Fetches a single metric for a single resource.GetMetricByName(ctx context.Context, name types.NamespacedName, info CustomMetricInfo, metricSelector labels.Selector) (*custom_metrics.MetricValue, error)// Fetch all metrics matching the input selector, i.e. all pods in a particular namespace.GetMetricBySelector(ctx context.Context, namespace string, selector labels.Selector, info CustomMetricInfo, metricSelector labels.Selector) (*custom_metrics.MetricValueList, error)// List all available metrics.ListAllMetrics() []CustomMetricInfo}
Implementing a Custom Metric Server
Our implementation of the custom metric server can be found here. Here's a high-level summary of the basic approach:
- In
ListAllMetrics, the custom metric server defines a custom metric,px-http-requests-per-second, on the Pod resource type. - The custom metric server queries Pixie's API every 30 seconds in order to generate the metric values (HTTP requests/second, by pod).
- These values can be fetched by subsequent calls to
GetMetricByNameandGetMetricBySelector. - The server caches the results of the query to avoid unnecessary recomputation every time a metric is fetched.
The custom metrics server contains a hard-coded PxL script (Pixie's query language) in order to compute HTTP requests/second by pod. PxL is very flexible, so we could easily extend this script to generate other metrics instead (latency by pod, requests/second in a different protocol like SQL, function latency, etc).
It's important to generate a custom metric for every one of your pods, because the Kubernetes autoscaler will not assume a zero-value for a pod without a metric associated. One early bug our implementation had was omitting the metric for pods that didn't have any HTTP requests.
Testing and Tuning
We can sanity check our custom metric via the kubectl API:
kubectl [-n <ns>] get --raw "/apis/custom.metrics.k8s.io/v1beta2/namespaces/default/pods/*/px-http-requests-per-second"
Let's try it on a demo application, a simple echo server. The echo server has a horizontal pod autoscaler that looks like this:
apiVersion: autoscaling/v2beta2kind: HorizontalPodAutoscalermetadata:name: echo-service-hpaspec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: echo-serviceminReplicas: 1maxReplicas: 10metrics:- type: Podspods:metric:name: px-http-requests-per-secondtarget:type: AverageValueaverageValue: 20
This autoscaler will try to meet the following goal: 20 requests per second (on average), per pod. If there are more requests per second, it will increase the number of pods, and if there are fewer, it will decrease the number of pods. The maxReplicas property prevents the autoscaler from provisioning more than 10 pods.
We can use hey to generate artificial HTTP load. This generates 10,000 requests to the /ping endpoint in our server.
hey -n 10000 http://<custom-metric-server-external-ip>/ping
Let's see what happens to the number of pods over time in our service. In the chart below, the 10,000 requests were generated at second 0. The requests were fast -- all 10,000 completed within a few seconds.

The number of pods increases in response to load, then decreases.
This is pretty cool. While all of the requests completed within 5 seconds, it took about 100 seconds for the autoscaler to max out the number of pods.
This is because Kubernetes autoscaling has intentional delays by default, so that the system doesn't scale up or down too quickly due to spurious load. However, we can configure the scaleDown/scaleUp behavior to make it add or remove pods more quickly if we want:
apiVersion: autoscaling/v2beta2kind: HorizontalPodAutoscalermetadata:name: echo-service-hpaspec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: echo-serviceminReplicas: 1maxReplicas: 10behavior:scaleDown:stabilizationWindowSeconds: 0scaleUp:stabilizationWindowSeconds: 0metrics:- type: Podspods:metric:name: px-http-requests-per-secondtarget:type: AverageValueaverageValue: 20
This should increase the responsiveness of the autoscaler. Note: there are other parameters that you can configure in behavior, some of which are listed here.
Let's compare the new autoscaling configuration to the old one applied with the exact same input stimulus: 10,000 pings from hey at second 0.
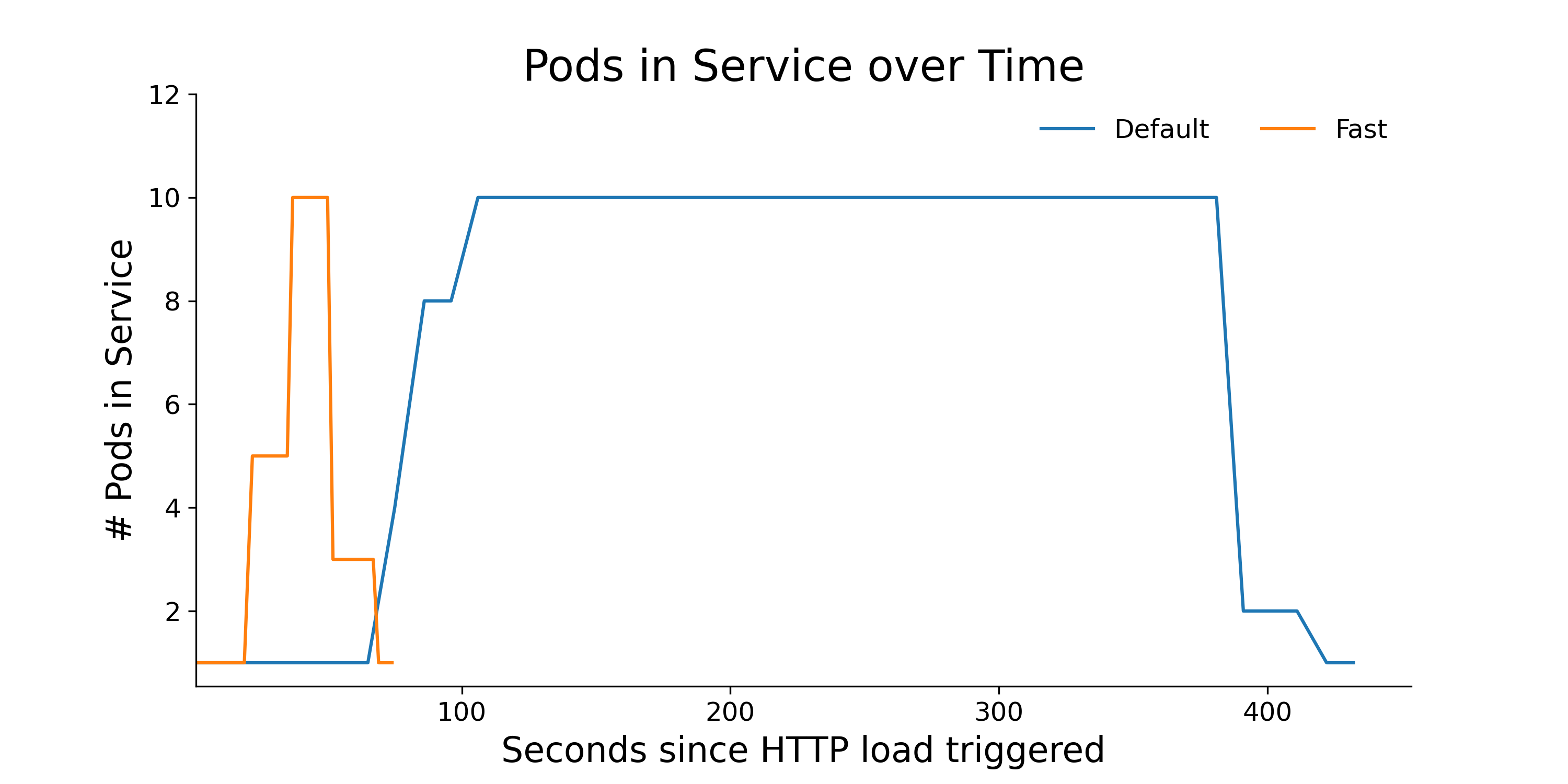
The number of pods increases/decreases faster when we reduce the stabilization window.
We can see that in comparison to the original configuration, the second version of our autoscaler adds and removes pods more quickly, as intended. The optimal values for these parameters are highly context-dependent, so you’ll want to consider the pros and cons of faster or slower stabilization for your own use case.
Final Notes and Extensibility
As mentioned, you can check out the full source code for the example here. Instructions for out-of-the-box use of the HTTP load balancer are also included. You can also tweak the script in the example to produce a different metric, such as HTTP request latency, or perhaps throughput of a different request protocol.
Thanks again to the Kubernetes Instrumentation SIG for making the framework for the custom metrics server!
Questions? Find us on Slack or Twitter at @pixie_run.
Related posts






Terms of Service|Privacy Policy
We are a Cloud Native Computing Foundation sandbox project.

Pixie was originally created and contributed by New Relic, Inc.
Copyright © 2018 - The Pixie Authors. All Rights Reserved. | Content distributed under CC BY 4.0.
The Linux Foundation has registered trademarks and uses trademarks. For a list of trademarks of The Linux Foundation, please see our Trademark Usage Page.
Pixie was originally created and contributed by New Relic, Inc.
This site uses cookies to provide you with a better user experience. By using Pixie, you consent to our use of cookies.